Overview
Today I’m going to skim over a recent passion project of mine that involves yoyo tricks. I have been throwing around yoyos since I was a teenager. Proof: Me, junior year, in the high school talent show (I’m no better today)
The purpose of this post is to provide a high-level overview of an end-to-end analysis in R, starting with unstructured data from YoYoTricks.com and ending with an interactive graph.
The motivation here was to obtain/create a catalog all yoyo tricks and how they relate to one another. This could be useful in determining the most foundational yoyo tricks, the most complex yoyo tricks, or to even in creating a recommendation engine to give users a selection of new tricks to learn based on what they know.
Scrape
So, the first step in the process was scraping this index to obtain a list of all yoyo trick names and the link to each trick tutorial. For this, I used R (rvest for HTML parsing, dplyr for transformations) and SelectorGadget to help define what to CSS classes to collect.

The code below will scrape the site map to obtain a data frame containing the trick name (title) and it’s corresponding link.
read_html('https://yoyotricks.com/sitemap/') %>%
html_nodes('.cat-item-1 a') %>%
html_attrs() %>%
lapply(function(row) {
data.frame(title=row['title'], link=row['href'], stringsAsFactors = FALSE)
}) %>%
bind_rows() %>%
filter(grepl(x=link, pattern='https://yoyotricks.com/yoyo-tricks/.+')) %>%
head(5) %>% kable()
| title | link |
|---|---|
| Looping Introduction | https://yoyotricks.com/yoyo-tricks/looping-introduction/139/ |
| String Tension Introduction - Fixing Twisted String | https://yoyotricks.com/yoyo-tricks/string-tension-introduction-fixing-twisted-string/334244/ |
| Choose and Setup the Perfect 2A Yoyo | https://yoyotricks.com/yoyo-tricks/choose-and-setup-the-perfect-2a-yoyo/333161/ |
| Swipe Double Green Triangle | https://yoyotricks.com/yoyo-tricks/swipe-double-green-triangle/333034/ |
| SOH-CAH-TOA Chopsticks | https://yoyotricks.com/yoyo-tricks/soh-cah-toa-chopsticks/333231/ |
Enrich
From here, I iterated over each trick page, scraping for enrichment data, such as trick category, tags, and (most importantly) references to other tricks.

| id | title | author | category | tags | link |
|---|---|---|---|---|---|
| 1 | Vanish Grind | Adam B. | Yoyo Tricks;Yoyo String Tricks (1A) | Green-Triangle;grind | https://yoyotricks.com/yoyo-tricks/vanish-grind/233896/ |
| 2 | Daniel Day-Lewis | Adam B. | Yoyo Tricks;Long String Tricks | https://yoyotricks.com/yoyo-tricks/daniel-day-lewis/232973/ | |
| 3 | Bouncy Castle | Jake E. | Yoyo Tricks;Yoyo String Tricks (1A) | Hop;Green-Triangle | https://yoyotricks.com/yoyo-tricks/bouncy-castle/228525/ |
| 4 | Monochrome | Cory H. | Yoyo Tricks;Yoyo String Tricks (1A) | Slack-String | https://yoyotricks.com/yoyo-tricks/monochrome/224191/ |
| 5 | Wax On, Wax Off | Jake E. | Yoyo Tricks;Yoyo String Tricks (1A) | Repeater;chopsticks | https://yoyotricks.com/yoyo-tricks/wax-on-wax-off/224190/ |
With an enriched trick catalog in-hand, I did some R-fu to produce a data frame of references between tricks.
In the table below, each number corresponds to a trick in the catalog table. The column weight indicates how many times the from trick references the to trick.
| from | to | weight |
|---|---|---|
| 1 | 294 | 1 |
| 2 | 90 | 2 |
| 2 | 235 | 2 |
| 2 | 281 | 2 |
| 2 | 335 | 3 |
| 3 | 4 | 2 |
Visualize & Explore
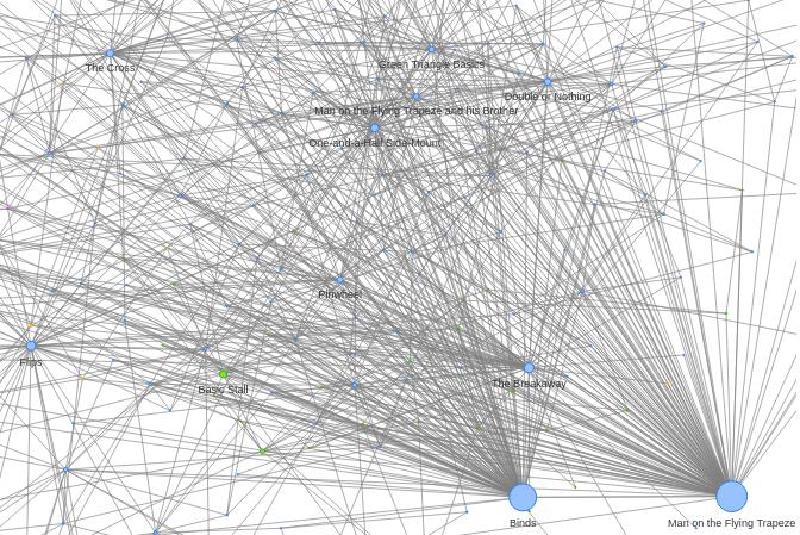
We now have everything needed to create a network graph visualization:
- nodes (trick catalog)
- edges (trick references)
Whoa, that’s messy! Regardless, underlying graph structure is useful for a variety of analyses.
Let’s see which tricks are referenced the most:

Next, let’s a few tricks that are the most similar, based soley on referenced tricks in common.
Note that the similarity measure is ignoring many important factors, such as trick style, category, etc, but this is sufficient for this exercise. Also, to simplify things, only complex tricks are considered (tricks which reference more than 5 other tricks).
At a glance, the tricks “Gravity Whip” and “Independent Tangler” have high similarity, as indicated by the width of the edge connecting them.
A glance at the sub-graph of these two similar shows they do indeed share many references to other fundamental tricks:
Just how similar are they? One measure, the jaccard similarity coefficient, is obtained by dividing the number of tricks in the intersection by the number of tricks in the union of the two trick reference sets.
## [1] "Similarity score: 0.555555555555556"
## [1] "55.56% of referenced tricks in common"
Conclusion
If you’re interested in further data exploration, I encourage you to spin up a kernel on Kaggle with the YoYoTricks dataset:
https://www.kaggle.com/dm3ll3n/yoyotricks
If you discover something interesting, let me know!
Until next time,
Donald
